Marketing STP
La segmentación de mercado es la primera fase del marketing STP (abreviaturas en inglés para Segmentation, Targeting y Positioning). El marketing STP, implica establecer los segmentos correctos para comercializar tu producto (Segmentación). Identificando el mercado objetivo adecuado (Focalización) y posteriormente posicionando el producto para recibir el máximo beneficio (Posicionamiento). Un aspecto importante del marketing STP es determinar los beneficios que tu producto ofrece y quiénes se beneficiarán al utilizarlo.
El primer paso del marketing STP es la segmentación del mercado. Para encontrar esos segmentos utilizaremos el Marketing Analytics, y la primera pregunta que debemos responder es: ¿Cuáles son las maneras de segmentar un mercado?
La segmentación de mercado puede basarse en diferentes aspectos: factores demográficos, psicográficos y geográficos. Por ejemplo, una universidad puede dividir sus clientes entre alumnos de pregrado y alumnos de postgrado, de manera de dividir sus esfuerzos de marketing en estos dos grupos.
Pero ¿cuales son beneficios de la segmentación de mercados?. Los diferentes segmentos tienen diferentes necesidades, por lo que las empresas necesitan desarrollar diferentes mensajes para cada segmento, esto incrementa la satisfacción de sus cliente al dirigirse a necesidades más específicas con los segmentos individuales del mercado que con el mercado general. la figura siguiente muestra un resumen de las principales ventajas de la segmentación de mercado.

Los enfoques de segmentación de mercado se pueden dividir en dos grupos; A priori y las Post Hoc. El enfoque a priori se refieren a los segmentos definidos antes de la investigación o análisis del mercado y las post hoc que son los segmentos definidos después del análisis del mercado.
En cuanto a las técnicas de segmentación la podemos dividir en dos grupos: descriptivas y predictivas. Las técnicas descriptivas describen las similitudes y diferencias entre los grupos y las técnicas predictivas se utilizan para predecir la relación entre las variables independientes y dependientes. Un resumen de las diferentes técnicas y sus categorías la podemos ver en la siguiente figura.

Hasta ahora hemos definido lo que significa la segmentación, pero ¿ Cómo se lleva a cabo el análisis de conglomerados o un análisis de la segmentación?. Existen muchas técnicas de agrupamiento, en este post voy a explicar dos técnicas y el objetivo de cada uno de éstas es formar grupos y estos grupos deben ser similares con respecto a los criterios que se está utilizando para segmentar el mercado dentro de un grupo, pero son diferentes a los otros grupos o segmentos.
Hierarchical Clustering
Esta técnicas es una de las más populares para la segmentación del mercado. Es un procedimiento numérico que intenta separar un conjunto de observaciones en grupos de abajo hacia arriba uniendo individuos secuencialmente hasta que obtengamos un grupo grande. Por lo tanto, esta técnica no requiere la especificación previa del número de grupos que queremos sementar, para el ejemplo utilizaremos el lenguaje R, un lenguaje muy común para el análisis de datos.
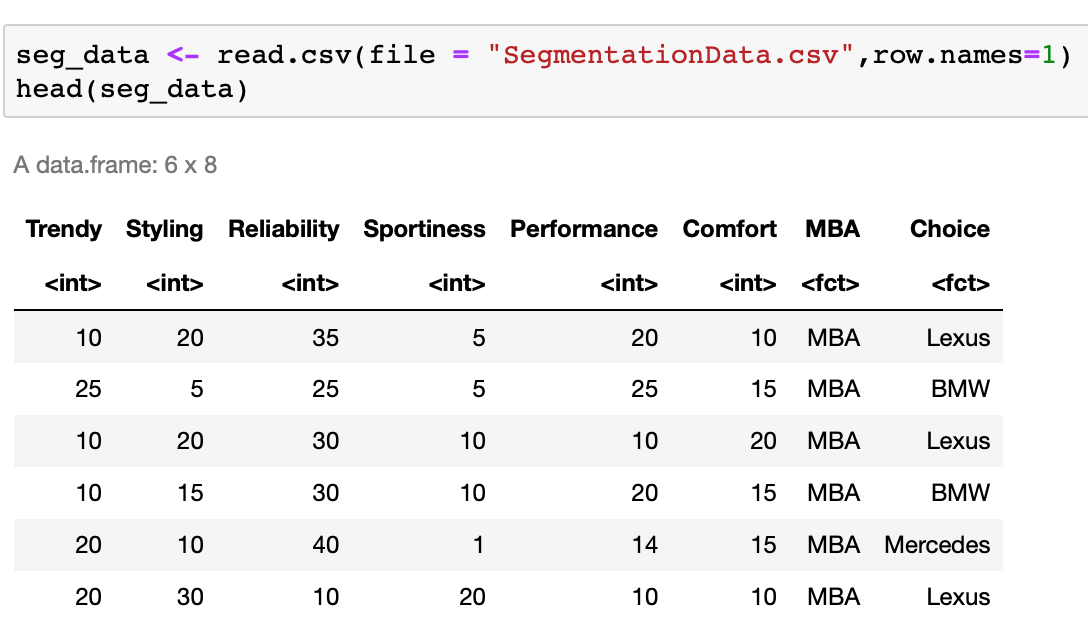
Primero importamos un conjunto de datos, en este caso una encuesta donde se le preguntan a estudiantes de MBA y Pregrado las características que debe tener un auto de lujo en términos de: estilo, moderno, fiabilidad, deportividad, rendimiento y comodidad en donde se le asigna un porcentaje a cada característica.
Antes de ejecutar el algoritmo hay que asegurarse que las variables tengas las mismas escalas, en este paso lo que necesitamos es la estandarización de la variable sobre todo si se miden con diferentes escalas, para ello seleccionamos las variables númericas y le aplicamos una distancia euclidiana.

Ahora usamos la función hclust () para aplicar la agrupación jerárquica en nuestros datos. Utilizamos el criterio Ward que tiene como objetivo minimizar la varianza dentro del grupo. Obtenemos el siguiente dendograma que puede ayudarnos a decidir el número de clústeres a retener.


Según el dendograma pareciera haber 3 o 4 grupos. Analizando con 4 grupos el primer grupo tiene 18 personas, el segundo grupo 29 personas, el tercer grupo 17 personas y el cuarto grupo sólo nueve personas. Si analizamos con 3 grupos pareciera que todos los del grupo cuatro se fueron al grupo uno, dejando sin modificaciones los grupos dos y tres.

Al parecer tres grupos es la cantidad de segmentos indicados, esta solución parece tener grupos de tamaños similares. Además, podemos caracterizar fácilmente cada uno de ellos. El primer grupo se preocupa por el rendimiento y la fiabilidad, mientras que el segundo grupo valora la comodidad y la deportividad, finalmente, el tercer grupo se preocupa por la apariencia, tal como lo muestra la figura siguiente:

Dado lo anterior, podemos agrupar los grupos por rendimiento, comodidad y apariencia. Un buen criterio para poder identificar a las personas que se encuentran de estos grupos es analizar las variables demográficas, este en este caso nuestra única variable demográfica es si el alumno es estudiante de MBA o de Pregrado, por lo tanto utilizaremos la técnica de CrossTable para analizar esta variable.
La tabla siguiente muestra en sus columnas, los tres grupos que se han encontrado a partir de la técnica Hierarchical Clustering, y las filas son el tipo de estudiante (MBA, Pregrado).
La tabla muestra que hay 24 estudiantes de MBA que representan el 33% de la muestra y 49 estudiantes de Pregrado que representan el 67% del total. Para los estudiantes de MBA 14 de los 24 estudiantes pertenecen al segmento de rendimiento, ósea un 58%. Por lo tanto, los estudiantes de MBA parecen más propensos a preferir un auto con mayor rendimiento. Por otra parte los estudiantes de pregrado 23 de ellos, ósea el 47% se ubica en el segmento de la comodidad, por lo que sus preferencias parecieran enfatizar en estilo y comodidad.

Es importante en la segmentación de mercado no perder el objetivo estratégico, para esto debemos responder la siguiente pregunta ¿ Los segmentos identificados nos conducen a diferentes estrategias de mercado? la segmentación de mercado es la búsqueda y la comprensión de los drivers de elección y las opciones que están disponibles para los consumidores. Al parecer según nuestro análisis nuestros drivers de elección son el rendimiento, comodidad y apariencia y las opciones disponibles son las marcas de los autos: BMW, Mercedes y Lexus. Por lo tanto esperamos que exista una relación entre los drivers y las opciones de compra. Aplicando la técnica CrossTable para comprar estas dos dimensiones obtenemos lo siguiente: 14 de las 27 personas del grupo de rendimientos eligieron BMW lo que representa un 52%, para el caso de la comodidad el 37% eligió Mercedes y 34% eligió BMW por lo que este grupo se encuentra divido entre estas dos marcas. Para el grupo de la apariencia el 43% eligió BMW por lo que esta marca parece ser atractivo en todos los segmentos

K-means Clustering
Ahora nos centramos en un método diferente llamado K-means. Este método nos obliga a especificar con antelación el número de grupos, sabemos por nuestro análisis anterior que tres grupos es el número más adecuado. Aplicando el algoritmo para tres grupos en esencia nos muestra las mismas agrupaciones de rendimiento, comodidad y apariencia, además nos muestra al individuo y su grupo correspondiente, así el individuo 1 tiene asignado el grupo 1, el individuo 2 tiene asignado el grupo 1 y así sucesivamente.

En este post intenté dar una visión general de la segmentación del mercado, también mostrar dos de las técnicas más utilizadas para la segmentación como lo son Hierarchical y K-means. Si bien estas técnicas son de gran utilidad para entender nuestros datos de clientes, el analista siempre debe darle una interpretación de negocio a los resultados y asegurarse que los grupos encontrados tengan sentido para las estrategias de marketing, al final esto no es una ciencia, es más un arte y el criterio del analista será muy importante en los análisis de segmentación.
![clip_image001[7]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEhAGXbmbUVKeK__eato10eIZ9bTB4a5MAIc7cQDj_HrRcd0pjTu5rmfQS-4TUz8kHnr24eQ-Y3kCvSwpeAt2HFA1APMi6s7UTnwc50o3kDUFQ7jztXDFMTVCRXMbixyxXGkAEDu0_4pUnbF/s1600-h/clip_image001%5B7%5D%5B2%5D.gif "clip_image001[7]")
![clip_image002[7]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEiE-PxYwsW1qeilv_GgSi0wRbYUFwbllYSThpZ0jF0e_XS1YWeclPFS9BmNZY8RkM9K-RlwEsO4A5hbGA6m5c45-dYq8-gWXXnbwpRn0M4nL3n66vI30SwjbuXaiLkFlsgCywM-Qxg2JECK/s1600-h/clip_image002%5B7%5D%5B2%5D.gif "clip_image002[7]")
![clip_image003[7]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEiT7D7MuRGIFDzU0NnsiFkVxRsETNC5zLQcgaQ21sdRJLdVQK5QFBk8kpQUZrHu6zl_3RBWOn48iQrC74PrGnIYQejZAdKlsoErUqBdi5hr3PqBwMjZCz2vTN1lYsFntDKhUAjyldjgJAL0/s1600-h/clip_image003%5B7%5D%5B2%5D.gif "clip_image003[7]")
![clip_image004[7]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEh_uuhflBmEs3VOc4FqRbOvfaBD9fzfr5I3IJFMddgT4BOu8zLU1PFPJ8aMm2P1IkTXAWRrAF84NwlQ5DDZtW3twxXqr19Tv3Du_ts3sdQ921rzzK5vMt6o9Y8NWeCS-3b93Glj5Hizlb3D/s1600-h/clip_image004%5B7%5D%5B2%5D.gif "clip_image004[7]")
![clip_image006[7]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEg9DHwVwvr4HL8ICdXMRnlKLc1fFGxxlyhiRqGCYIUdyTs33OCnBFvz-5NWgPq6Iw9Fxs7NiAt0zqTjT7M2N9ocdyUr9PVzxF_mBVb74cCo800u3tsR_9QDB4v_hDg5fIMqdyxT-_A3cB-G/s1600-h/clip_image006%5B7%5D%5B2%5D.jpg "clip_image006[7]")
![clip_image008[7]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEgDbtD0JLl6KHWGztUEzDV95wO1ivjccIyoES5AiwokAQ6l4uiJVzQYPKeGo9kU6hPySdFeo1uq9-U58hlOtQeEP3PYlQSJUMGA9c-4toygb2DKkeRv2URQVZOtPb8QXnld8m7s-SdlALCB/s1600-h/clip_image008%5B7%5D%5B2%5D.jpg "clip_image008[7]")
![clip_image010[7]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEi91YuYMZhVy03G_MQ4J6abVmM4nZlS0p7CnB_W3tUSRG4Y6xEAx-8r8FKjjpvW5-1tBDY4dFrWwzcX4Tr3Oe7bSpiY8kS7lL34tjTJ-BxJf0BgPnzvqUPxK8RGj-_SAJX2J2EycpXJWt8j/s1600-h/clip_image010%5B7%5D%5B2%5D.jpg "clip_image010[7]")
![clip_image014[7]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEjRqREWcSyMvliRQoOdPvkVl9WPC1Jwy5vin07pEBjQjUt4A7-LgKQwsJ5Vt2j7L38tIJ5RGwfk8amG8wLVrY4_8tJjDtvm1HAgpKO4JdKJtEz5Z2vcfNJQtF-CJ8A2wr0yTgg94957fuVi/s1600-h/clip_image014%5B7%5D%5B2%5D.jpg "clip_image014[7]")
![clip_image015[7]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEgicNJQ7WbahWTvo6Z_qMAVEc2okL8o0tqgPvqsCFvHH8GZv1v1U7Lvajc7qqWGijjgdgP9sHiZsYMhohAuUTZKpb1rq9V8VWYVmpePgqTgjeg17FslIPRC8d_7I75aEg0LBTsUOljfp-1W/s1600-h/clip_image015%5B7%5D%5B2%5D.gif "clip_image015[7]")
![clip_image017[7]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEjIuF0BlW9icSBtzSe5yhQEMWORRlsCbMID7lBh4ArRElvZZg7YEQWcmEWR8Fv9hTdNDwqiY4-9dkRcgIjUzHBw9afEhyphenhyphenAAABFxzUKouFLLQcTgR6b8qXnVfiW16FXh_eu847AVODrCd6yx/s1600-h/clip_image017%5B7%5D%5B2%5D.jpg "clip_image017[7]")
![clip_image018[7]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEgBvOMKvfi3ce4eDdStGzSpfBYwTmuaHnfcXSN3Ci8MIgg7rkkCPGe_P4cUTUKcHyErc4dTGbXqGVIzCQlkNRcu8ZWvEOb4zIykQtpVFpZLDLHYYScqoHnax4IxGt60Q8_oQR3j5lWu8mp2/s1600-h/clip_image018%5B7%5D%5B2%5D.gif "clip_image018[7]")
![clip_image019[7]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEi3WSxCTZdZVRXGnW43PIRgQ4KQbvT9NttAEyXbiLuw2AWU-S4OuGFyZbFa_ELpfLy-Tj0d5Egx21I5K6gsxTkYZrIuxapJzJiGflMpgG7wytHLmzrvMf3Ma1nSQ5YX0WCleqqMzHqYbR-W/s1600-h/clip_image019%5B7%5D%5B2%5D.gif "clip_image019[7]")
![clip_image021[7]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEgke5O0uxT0_7kcnS9Vyu6OI_Idt9h0IrxNCBpIPCaM5_Mhye5zVPO1zy3AR_BbNsaTaEmN41F0dluCSrup-y5dO1tQXyxyn5a6wnGzrZaFwc7_OxYWjCuqblWVlmaHFQ_r5MUCeq-LcZOV/s1600-h/clip_image021%5B7%5D%5B2%5D.jpg "clip_image021[7]")
![clip_image023[7]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEgt8BRcLrIvrQ1MtHc04sXOMOZgxxniB0S_PDcBJqR7HX-AHRCWoocYrPMNVgb9cOijylatBBYH4C5tP_SMAu15xqbB70BcN-DpFBm_0Mf5879Rw4J8y1HbmCSvA6s5Ztxvw7ajtbRq5Yx2/s1600-h/clip_image023%5B7%5D%5B2%5D.jpg "clip_image023[7]")
![clip_image025[7]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEhptdrAnYD8aYvA5WCofGbDk3qniLza2FzK9lUM8tJAZbr1JG-qKIPw8yvF1LuaLFYv8qfpWOSVGYzg3qVYG6c9VZhtgzVSWTG1eQr-Z3uQGC_KyWOUjp01Kg81RqDKUk7N5klSXxlM2ig2/s1600-h/clip_image025%5B7%5D%5B2%5D.jpg "clip_image025[7]")



